First off let’s brush up on what is the token ring and the partitioners so that we are one the same page.
Token Ring
Cassandra’s data is distributed across a cluster in the form of a ring. This ring is a goes starts at the position 0 and goes on until the position 2127, both these positions and all of the ones between them are known as tokens and nodes in the cluster have a certain range of tokens that are their responsibility. Here is an example where each node is responsible for 25% of the token ring, borrowed from Datastax documentation:
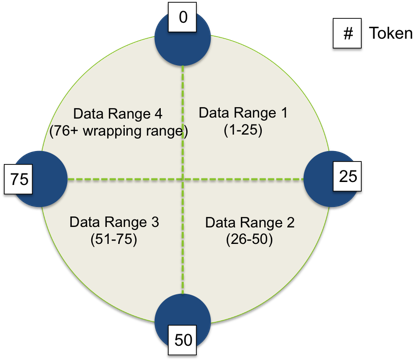
Cassandra Partitioners
There are two basic types of partitioners that come out of the box with Cassandra, the Random Partitioner (RP) and the Order Preserving Partitioner (OPP). What they do is just decide to which part of the token ring each node is responsible for. If you use RP the MD5 hash of the row will be used to map onto the ring, on the other hand if you use OPP the actual value of the row is truncated so that it fits in the ring’s range and then the row is mapped accordingly.
When to use OPP
Well, the blunt answer is never. Since OPP maps the row keys directly it is very prone to create hotspots (data that is frequently accessed or a lot of the data may be assigned to the same node), which may and probably will destroy all your hopes and dreams of scalability. And now you ask, but what if I want to perform range queries, is that impossible?
The answer is of course it is possible, just use RP and index your row keys. So, the strategy is to have a Column Family where each row has the name of another Column Family and the columns are its row keys, since RP only applies to the row keys you can have the columns ordered.
Your data model will look something like this:
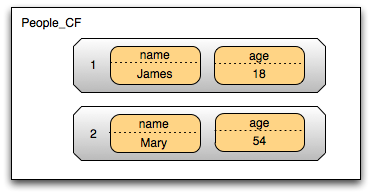
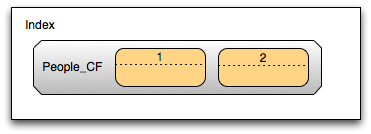
Your actual data will then be randomly distributed across the cluster and if you need to perform a range query you just have to get the range from the index columns first ant then multiget the data. It is true that this introduces one more step for each range query performed, but this is a much lesser price to pay than the one you pay with OPP, since now your database will actually scale which means you can add more machines if it does not perform as well as you wished.
DISCLAIMER: This post reflects my honest opinion, but it is nevertheless a personal opinion.